2.3) Verilog - le coeur
Le cœur est un RISC
16bits, avec un décodage d’instruction très simple.
C’est
du RISC, donc sans microcode. Les opérations sont donc très
élémentaires. Le CPU, en lui-même, est incapable de générer des
opérations complexes. Toute la complexité que l’on trouve dans le
microcode sur un CPU CISC, se retrouve dans le compilateur. C’est le
compilateur qui va générer une séquence d’instructions élémentaires à
partir d’une instruction plus complexe. Le code exécutable généré est
donc très volumineux, beaucoup plus que pour un CPU CISC, mais ça n’est
pas un problème, vu les 2Mo de RAM.
Le datapath du cœur,
c’est du « load and store », architecturé autour du registre central C,
chaque instruction ne peut manipuler qu’un seul autre registre ou le
port externe, et ce dans un seul sens (lecture ou écriture).
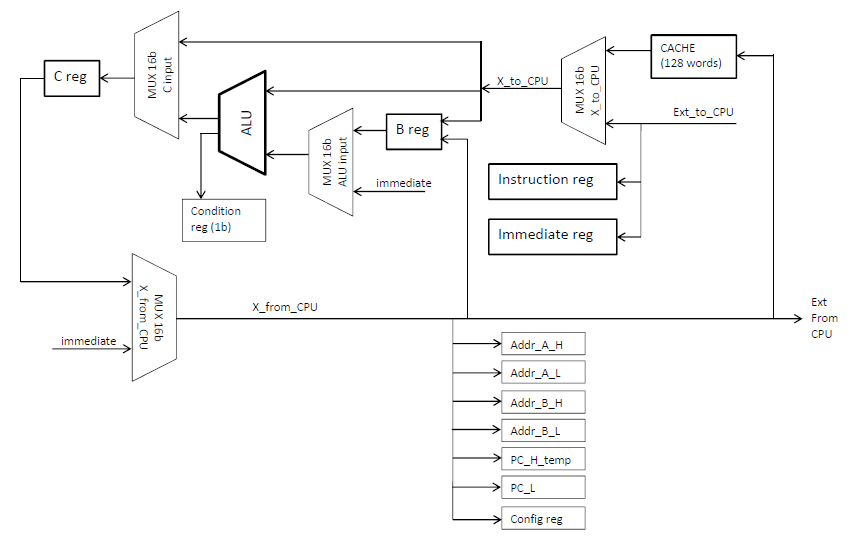
Une instruction peut prendre une donnée 16 bits « immediate » en option, directement placée dans le code exécutable immédiatement après l’instruction qui appelle la valeur immediate. Une instruction avec immediate est donc écrite sur 2x16bits dans le code exécutable.
L'ALU manipule des entiers 16 bits, c'est amplement suffisant.

Cache :
J’ai
placé une mémoire cache de 128 mots de 16bits, que l’on peut adresser
directement via l’instruction. 7 bits de l’instruction (partie micro
adresse) servent à cet adressage.
Ca accélère grandement l’accès
aux données intermédiaires des calculs, et la manipulation répétitive
des mêmes données. Le compilateur utilise systématiquement ce cache
pour les données intermédiaires des calculs et des « expressions ».
Cette
mémoire cache est accessible à la même vitesse que la mémoire externe.
Donc j’aurais pu m’en passer en implémentant un mécanisme de « zéro
page », concept que j’ai malheureusement découvert après coup.
Optimisations
configurables:
Les
3 optimisations suivantes ont été codées avec comme objectif
d’accélérer la manipulation d’images, de sprites depuis le coeur.
On active ces 3 mécanismes (post-incrément, loop counter et do not copy
if zero) via le registre « config ».
Attention, le compilateur n’a pas conscience de ces options. Pour les
utiliser, il faut coder en assembleur.
- Le cœur possède un « loop counter » hardware pour exécuter une séquence d’instructions répétitives un certain nombre de fois, sans avoir à calculer en soft de condition d’arrêt (for i = 1 to 10). Ce compteur est décrémenté à chaque « goto », et la condition d’arrêt est évaluée en hardware. La valeur initiale du loop counter (=le nombre de boucles à exécuter) doit être placée dans le registre « loop counter ».
- Le cœur possède 2 registres d’adresses séparés (A et B), avec gestion des incréments automatiques (post incrément) des adresses pour chacun des 2, ce qui permet de faire des copies de données rapides d’un endroit de l’espace mémoire à l’autre. Les post-incréments peuvent être configurés à +1 ou +2, selon qu’on manipule des mots de 8 bits ou 16bits.
- Il y a aussi une
configuration « do not copy if zero » qui permet de gérer en hardware
la transparence des sprites copiés par logiciel. Dans ce cas, la
couleur 0x00 veut dire « transparent ».
Calcul des adresses :
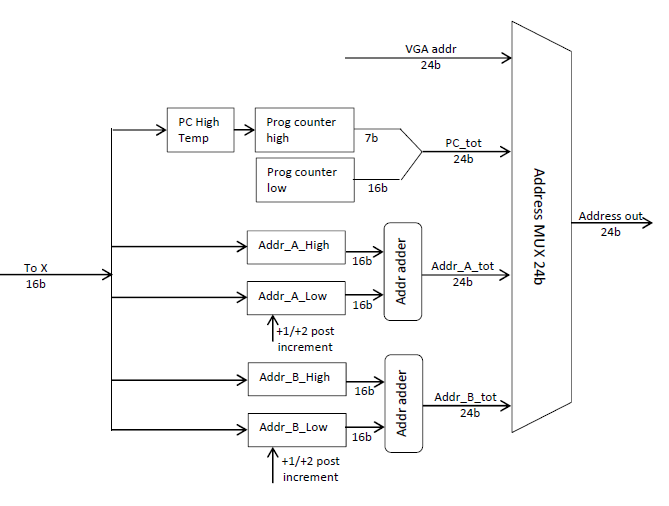
Les adresses 24bits sont calculées en hardware à partir d’une addition de 2 adresses 16bits. C’est pratique pour manipuler des grands tableaux (ou images) qui ne sont pas alignés sur des multiples de 64ko.

Pour le program counter, il n’y a pas d’additionneur, c’est inutile.

Attention, les adresses manipulées par le « program counter » n’ont pas la même unité que les adresses manipulées pour les données. Le program counter compte en 16bits (les instructions) alors que les adresses de données comptent en 8bits, quelle que soit la taille des données manipulées. Donc il y a un décalage d’1 bit (donc un facteur 2) entre une adresse « data » et une adresse « program counter ».
Erreurs :
Le
cœur, c’est la partie que j’ai codée en premier, et sur laquelle j’ai
fait le plus d’erreurs de conception. J’aurais pu obtenir un cœur plus
performant, par exemple si j’avais fait du registre C un vrai
accumulateur.
L’architecture « load and store » est très simple,
mais dégrade beaucoup les performances, et n’a surtout aucune raison
d’être sur un FPGA.
Une autre erreur : j’ai intégré un diviseur
dans la partie ALU. Ca bouffe un nombre impressionnant de blocs dans le
FPGA, et c’est assez inutile.
Quand je l’ai conçu, je n’avais pas conscience de tout ça, je m’en suis
rendu compte à postériori.
Mais je n’ai pas voulu remettre en cause tout ça, car il me restait
énormément de travail pour finir le projet.